Het opzetten van Disaster Recovery as a Service (DRaaS) is cruciaal voor organisaties die de nadelige gevolgen van onvoorziene rampen willen beperken. Deze uitgebreide gids gaat in op het opzetten van een robuust DRaaS-raamwerk met behulp van AWS Elastic Disaster Recovery voor bedrijfskritische toepassingen. De gids is opgebouwd rond twee fundamentele DRaaS-metrieken: Recovery Point Objective (RPO) en Recovery Time Objective (RTO), die in wezen de aanvaardbare drempels voor respectievelijk gegevensverlies en operationele downtime meten.
RPO en RTO begrijpen
RPO verwijst naar de maximale duur van gegevensverlies die een organisatie kan verdragen na een ramp. Het is een terugkijkende metriek, die zich uitstrekt vanaf het moment dat de ramp zich voordeed. Een financiële dienstverlener die veel transacties verwerkt, heeft bijvoorbeeld een RPO van bijna nul nodig vanwege de hoge kosten van gegevensverlies, terwijl een klein bedrijf met minder kritieke gegevens een langere RPO kan hanteren en het verlies van enkele uren aan e-mails kan tolereren.
RTO daarentegen kijkt vooruit en schat de tijd in die nodig is om de bedrijfsactiviteiten te herstellen naar de toestand van voor de ramp. Dit omvat het herstel van servers, databases en toegang tot kritieke applicaties. De RTO is cruciaal voor het evalueren van de directe en indirecte kosten die gepaard gaan met uitval, variërend van verloren omzet op een belangrijke winkeldag tot de gevolgen voor de productiviteit van verschillende afdelingen.
Rampherstel voor bedrijfskritische toepassingen met AWS Elastic Disaster Recovery
Organisaties die een rampherstelplan nodig hebben dat zorgt voor minimale downtime en gegevensverlies voor hun bedrijfskritische applicaties, kunnen zich wenden tot AWS Elastic Disaster Recovery, dat een oplossing biedt die snel, betrouwbaar herstel ondersteunt voor applicaties op locatie en in de cloud. Door gebruik te maken van betaalbare opslagopties en minimale computermiddelen biedt het een efficiënte DR-opstelling.
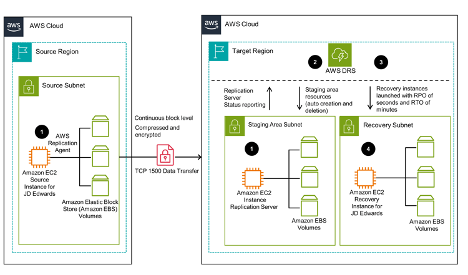
Belangrijkste onderdelen en vereisten
Om deze DR-strategie te implementeren, moet aan bepaalde voorwaarden worden voldaan:
- - Actief AWS-account: Essentieel voor toegang tot AWS-services.
- - Bedrijfskritische applicaties die draaien op Oracle Database, Microsoft SQL Server of IBM DB2 moeten operationeel zijn op een Amazon EC2-instance in één AWS-regio.
- - AWS IAM-rol: Nodig voor het configureren van Elastic Disaster Recovery.
- - Netwerkconfiguratie: Moet overeenkomen met de connectiviteitsvereisten van Elastic Disaster Recovery.
Beperkingen zijn onder andere de incompatibiliteit met Amazon RDS (behalve voor het gebruik van Amazon's cross-Region copy functionaliteit) en een limiet op het aantal servers dat kan worden gerepliceerd met behulp van Elastic Disaster Recovery in een enkele AWS account.
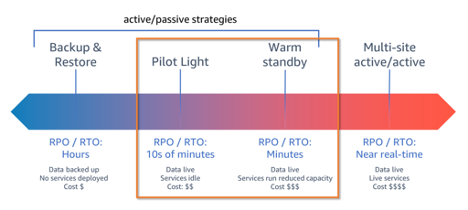
De waakvlamstrategie
Bij deze DR-strategie wordt een minimale versie van de omgeving in stand gehouden, klaar om te worden opgeschaald bij een ramp. In eerste instantie wordt een replicatieserver opgezet om gegevens van de brondatabase te spiegelen, waarbij de eigenlijke databaseserver pas beschikbaar wordt gesteld wanneer een DR-oefening wordt gestart. Deze aanpak verlaagt de kosten aanzienlijk doordat een continu draaiende databaseserver op de DR-locatie niet nodig is.
AWS Elastic Disaster Recovery configureren
Het instellen omvat het aanmaken van een IAM-rol voor Elastic Disaster Recovery en het configureren van het netwerk volgens de connectiviteitsvereisten. Het proces omvat:
- – Replicatienetwerk instellen: Uw primaire AWS-regio vaststellen en de DR-regio identificeren.
- – Bepaling van RPO en RTO: Je tolerantieniveaus bepalen voor gegevensverlies en downtime.
- – Replicatieserver initialisatie: Beginnen met een kleinere instantie voor replicatie, die kan worden opgeschaald voor hersteloperaties.
DR implementeren met AWS Elastic Disaster Recovery
Het implementatieproces omvat verschillende belangrijke stappen:
- 1. Installatie van de AWS Replication Agent: Cruciaal voor het starten van gegevensreplicatie vanaf de bronservers.
- 2. Continue gegevensreplicatie: Zorgt ervoor dat de gegevens van de DR site de primaire site tot het laatste replicatiepunt weerspiegelen.
- 3. Start Instellingen Configuratie: Voor herstelinstanties, inclusief instancesoort, beveiligingsinstellingen en netwerkconfiguraties.
- 4. DR Boorinitiatie: Testen van het herstelproces zonder de productieomgeving of de lopende replicatie te beïnvloeden.
Failover- en Failback-processen
Een succesvol DR-plan bevat gedetailleerde failover- en failback-procedures die de bedrijfscontinuïteit garanderen:
Failover: Omleiden van verkeer van het primaire systeem naar het DR-systeem.
Terugvallen: Keert het proces om, waardoor bewerkingen na herstel terug worden gebracht naar het primaire systeem.
Optimalisatie en automatisering
Voor uw bedrijfskritische applicatie kan optimalisatie databasemanagementstrategieën omvatten, zoals het verplaatsen van file share-objecten naar de database, om het herstelproces te stroomlijnen. Automatisering, met behulp van tools zoals AWS Lambda of AWS Step Functions, kan de handmatige inspanning die nodig is voor het failover- en failbackproces aanzienlijk verminderen.
Beste praktijken
Het volgen van best practices zorgt ervoor dat de DR-strategie zowel effectief als efficiënt is:
- – Regelmatig testen: Uitvoeren van DR-oefeningen om ervoor te zorgen dat het systeem werkt zoals verwacht.
- – Bewaking: Het replicatieproces en de gezondheid van de DR-opstelling in de gaten houden.
- – Documentatie: Gedetailleerde documentatie bijhouden van het DR-plan, inclusief rollen, verantwoordelijkheden en procedures.
Conclusie
Het implementeren van disaster recovery voor bedrijfskritische applicaties met behulp van AWS Elastic Disaster Recovery vereist zorgvuldige planning en overweging van verschillende factoren, waaronder RPO en RTO, applicatiearchitectuur en AWS-services. Door de beschreven stappen en best practices te volgen, kunnen organisaties een veerkrachtige DRaaS-oplossing opzetten die downtime en gegevensverlies minimaliseert en bedrijfscontinuïteit garandeert bij rampen.