Setting up Disaster Recovery as a Service (DRaaS) is pivotal for organizations looking to mitigate the adverse impacts of unforeseen disasters. This comprehensive guide delves into establishing a robust DRaaS framework using AWS Elastic Disaster Recovery for mission critical applications. It is structured around two fundamental DRaaS metrics: Recovery Point Objective (RPO) and Recovery Time Objective (RTO), which essentially measure the tolerable thresholds for data loss and operational downtime, respectively.
Understanding RPO and RTO
RPO refers to the maximum duration of data loss an organization can withstand post-disaster. It is a backward-looking metric, stretching from the disaster occurrence point. For example, a financial services firm handling numerous transactions would require a near-zero RPO due to the high cost of data loss, whereas a small business with less critical data might manage with a longer RPO, tolerating the loss of several hours’ worth of emails.
RTO, conversely, looks forward, estimating the time required to restore business operations to their pre-disaster state. This includes the restoration of servers, databases, and access to critical applications. The RTO is crucial for evaluating the direct and indirect costs associated with downtime, ranging from lost sales on a major shopping day to the productivity impacts on various departments.
Disaster Recovery for Mission Critical Applications Using AWS Elastic Disaster Recovery
Organizations requiring a disaster recovery plan that ensures minimal downtime and data loss for their mission critical applications can turn to AWS Elastic Disaster Recovery which offers a solution that supports fast, reliable recovery for on-premises and cloud-based applications. By leveraging affordable storage options and minimal compute resources, it provides an efficient DR setup.
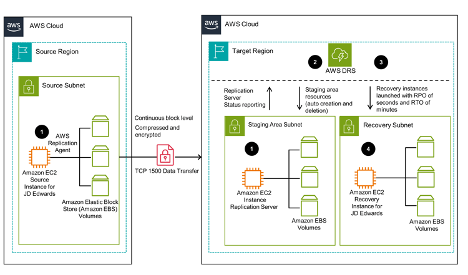
Key Components and Prerequisites
To implement this DR strategy, certain prerequisites must be met:
- – Active AWS Account: Essential for accessing AWS services.
- – Mission Critical Applications running on Oracle Database, Microsoft SQL Server, or IBM DB2 must be operational on an Amazon EC2 instance in one AWS Region.
- – AWS IAM Role: Necessary for configuring Elastic Disaster Recovery.
- – Network Configuration: Must align with Elastic Disaster Recovery’s connectivity requirements.
Limitations include the incompatibility with Amazon RDS (except for using Amazon’s cross-Region copy functionality) and a cap on the number of servers that can be replicated using Elastic Disaster Recovery in a single AWS account.
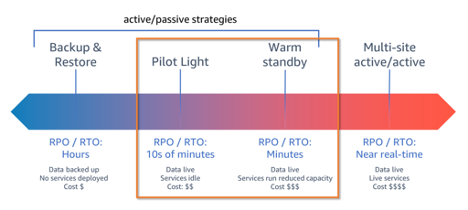
The Pilot Light Strategy
This DR strategy involves maintaining a minimal version of the environment, ready to be scaled up in a disaster. Initially, a replication server is set up to mirror data from the source database, with the actual database server provisioned only upon initiating a DR drill. This approach significantly reduces costs by avoiding the need for a continuously running database server in the DR site.
Configuring AWS Elastic Disaster Recovery
Setting up involves creating an IAM role for Elastic Disaster Recovery and configuring the network as per the connectivity requirements. The process includes:
- – Replication Network Setup: Establishing your primary AWS Region and identifying the DR Region.
- – RPO and RTO Determination: Defining your tolerance levels for data loss and downtime.
- – Replication Server Initialization: Starting with a smaller instance for replication, which can be scaled up for recovery operations.
Implementing DR with AWS Elastic Disaster Recovery
The implementation process entails several key steps:
- 1. Installation of the AWS Replication Agent: Crucial for initiating data replication from the source servers.
- 2. Continuous Data Replication: Ensures the DR site’s data mirrors the primary site up to the last replication point.
- 3. Launch Settings Configuration: For recovery instances, including instance type, security settings, and network configurations.
- 4. DR Drill Initiation: Testing the recovery process without affecting the production environment or ongoing replication.
Failover and Failback Processes
A successful DR plan includes detailed failover and failback procedures, ensuring business continuity:
Failover: Involves redirecting traffic from the primary system to the DR system.
Failback: Reverses the process, bringing operations back to the primary system after recovery.
Optimization and Automation
For your mission critical application, optimization might include database management strategies, like moving file share objects into the database, to streamline the recovery process. Automation, using tools like AWS Lambda or AWS Step Functions, can significantly reduce the manual effort required in the failover and failback processes.
Best Practices
Adhering to best practices ensures the DR strategy is both effective and efficient:
- – Regular Testing: Conducting DR drills to ensure the system works as expected.
- – Monitoring: Keeping an eye on the replication process and the health of the DR setup.
- – Documentation: Maintaining detailed documentation of the DR plan, including roles, responsibilities, and procedures.
Conclusion
Implementing disaster recovery for Mission Critical applications using AWS Elastic Disaster Recovery requires careful planning and consideration of various factors including RPO and RTO, application architecture, and AWS services. By following the outlined steps and best practices, organizations can establish a resilient DRaaS solution that minimizes downtime and data loss, ensuring business continuity in the face of disasters.